In the last 2 posts we saw how to install HANA DB on 2 nodes and how to setup site replication between those 2 nodes here and here
In this post we will see how to set up HA between both sites.
Please Note: This guide is prepared with Reference from the official documentation here
To setup HA please have SBD configured on both nodes.
For this setup I have used multipath for consistency.
Configure Multipath
First make sure you have an Iscsi server which exposes a device of 2 GB as Iscsi target.
In both nodes make sure Iscsi client is configured and connected.
To setup iSCSI in SLES for SAP refer the official guide here
Once configured you should be able to see the device in the device list
fdisk -lNext install multipath if not already installed
zypper install multipath*Start and enable multipathd.service
systemctl enable multipathd.service
systemctl start multipathd.serviceStart and enable chronyd.service
systemctl enable chronyd.service
systemctl start chronyd.serviceGenerate the multipath configuration file using the command
multipath -T >/etc/multipath.confThis command should automatically configure multipath for the sbd device, however alias won’t be added.
Edit the multipath.conf file and add the alias for the device.
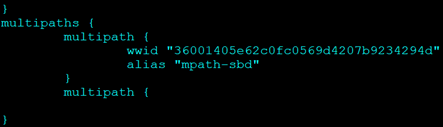
Reload Multipath Service
service multipathd reloadNew device should be available in fdisk -l

This is the device we will use in HA configuration.
Repeat the steps on Node 2
HA installation
Initiate HA installation on Node 1
ha-cluster-init -U -s /dev/mapper/mpath-sbdAnswer “No” for VIP and QDevice.
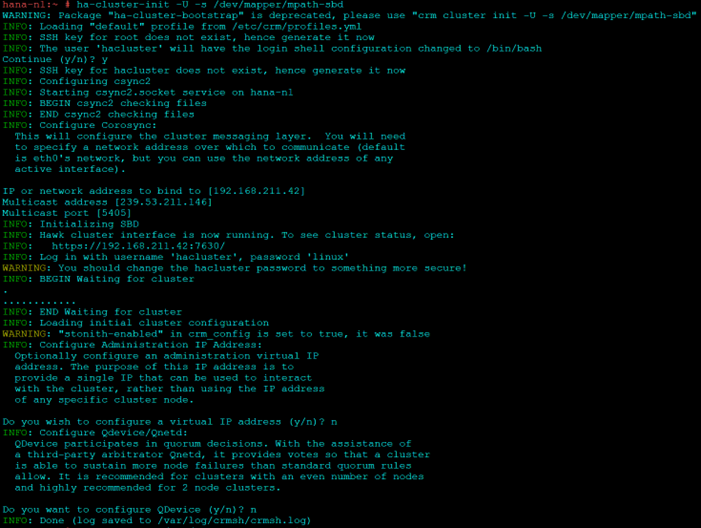
Commands to check if SBD has been configured correctly
egrep -v "(^#|^$)" /etc/sysconfig/sbd
sbd -d /dev/mapper/mpath-sbd dump
sbd -d /dev/mapper/mpath-sbd listOn second Node to join this cluster
ha-cluster-join -c 192.168.211.42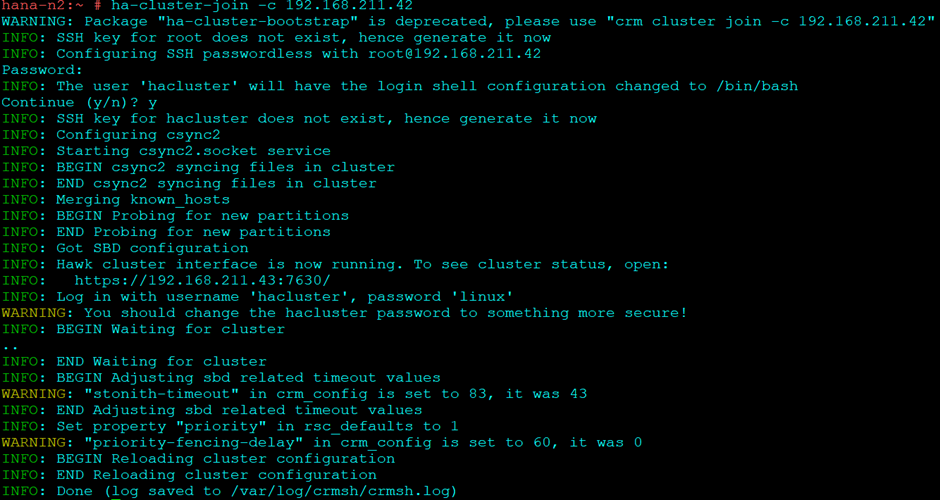
To check the cluster: (On both nodes)
systemctl status pacemaker
systemctl status sbd
crm cluster start
crm status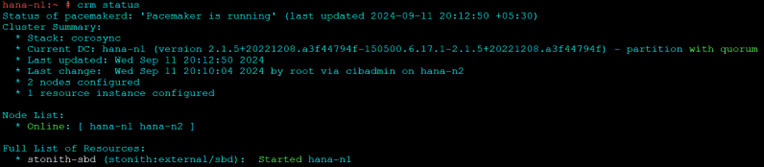
HANA Cluster Configuration
Now that the initial cluster is setup lets configure SAP HANA multistate using separate configuration files and loading it into cluster.
The syntax would be as below
vi crm-fileXX
crm configure load update crm-fileXXCluster bootstrap
vi crm-bs.txt
###
# enter the following to crm-bs.txt
property cib-bootstrap-options: \
stonith-enabled="true" \
stonith-action="reboot" \
stonith-timeout="150" \
priority-fencing-delay="30"
rsc_defaults rsc-options: \
resource-stickiness="1000" \
migration-threshold="5000"
op_defaults op-options: \
timeout="600" \
record-pending=trueLoad config to cluster
crm configure load update crm-bs.txtSTONITH Device
vi crm-sbd.txt
###
# enter the following to crm-sbd.txt
primitive stonith-sbd stonith:external/sbd \
params pcmk_delay_max="15"Load Config to Cluster
crm configure load update crm-sbd.txtSAP HANA Topology
vi crm-saphanatop.txt
###
# enter the following to crm-saphanatop.txt
primitive rsc_SAPHanaTop_HA1_HDB10 ocf:suse:SAPHanaTopology \
op monitor interval="10" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="HA1" InstanceNumber="10"
clone cln_SAPHanaTop_HA1_HDB10 rsc_SAPHanaTop_HA1_HDB10 \
meta clone-node-max="1" interleave="true"Load config to cluster
crm configure load update crm-saphanatop.txtSAP Hana
vi crm-saphana.txt
# enter the following to crm-saphana.txt
primitive rsc_SAPHana_HA1_HDB10 ocf:suse:SAPHana \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op monitor interval="60" role="Master" timeout="700" \
op monitor interval="61" role="Slave" timeout="700" \
params SID="HA1" InstanceNumber="10" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false" \
meta priority="100"
ms msl_SAPHana_HA1_HDB10 rsc_SAPHana_HA1_HDB10 \
meta clone-max="2" clone-node-max="1" interleave="true" maintenance=trueLoad config to cluster
crm configure load update crm-saphana.txtVirtual IP Address
# vi crm-vip.txt
# enter the following to crm-vip.txt
primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \
op monitor interval="10s" timeout="20s" \
params ip="192.168.1.20"Load config to cluster
crm configure load update crm-vip.txtActivating multi-state resource for cluster operation
crm resource refresh msl_SAPHana_HA1_HDB10
crm resource maintenance msl_SAPHana_HA1_HDB10 offThat’s it you successfully configured HANA with replication and HA.
If you go to your HAWK portal, you should see as below:

Testing
Test 1:
Stop Hana on node 1
HDB stopAutomatic take over should happen and node 2 should be promoted.
Refresh cluster resource and check status
crm resource refresh rsc_SAPHana_HA1_HDB10 hana-n1
crm statusNode 1 should start and stay as secondary
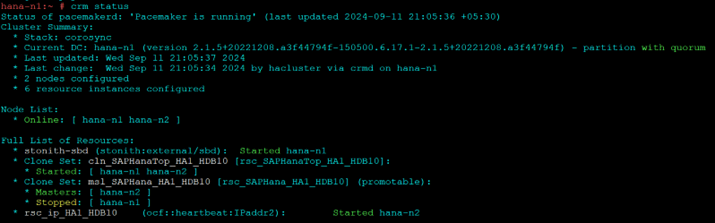
To Recover
hdbnsutil -sr_register --name=WDF --remoteHost=hana-n2 --remoteInstance=10 --replicationMode=sync --operationMode=logreplayTest 2
Stop Hana on node 2
HDB stopAutomatic take over should happen and node 1 should be promoted
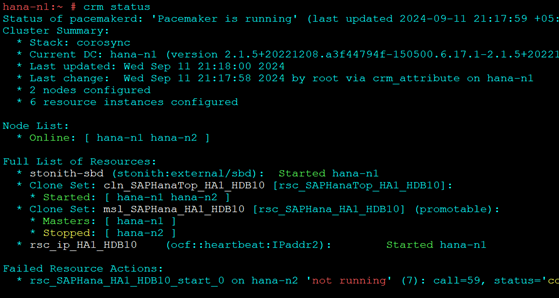
To Recover on Node 2
hdbnsutil -sr_register --name=ROT --remoteHost=hana-n1 --remoteInstance=10 --replicationMode=sync --operationMode=logreplayNode 2 should start and stay as secondary
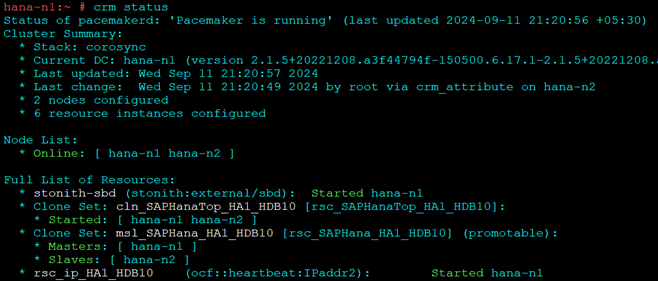
That is it, we have successfully setup High Availability for a 2-Node HANA DB Cluster with Site Replication.
1 thought on “Set up High Availability between 2 HANA DB Sites”